
Sunday, 1 March 2020
Tuesday, 14 January 2020

How to Login Dark Web
How to Login Dark Web
Step 1. Get yourself a good VPN service
That means one that doesn’t keep logs, has no DNS leaks, is fast, is compatible with Tor, and which (preferably) accepts Bitcoin as payment. Here are some of the most trustworthy. If you’re new to VPNs, this handy tutorial will teach you everything you need to know.
For this example, we’re using the VPN CyberGhost. Open the VPN and connect to a server in your chosen location. This will change your IP address, making it appear as if you’re connecting to the web from a different location than your real one.
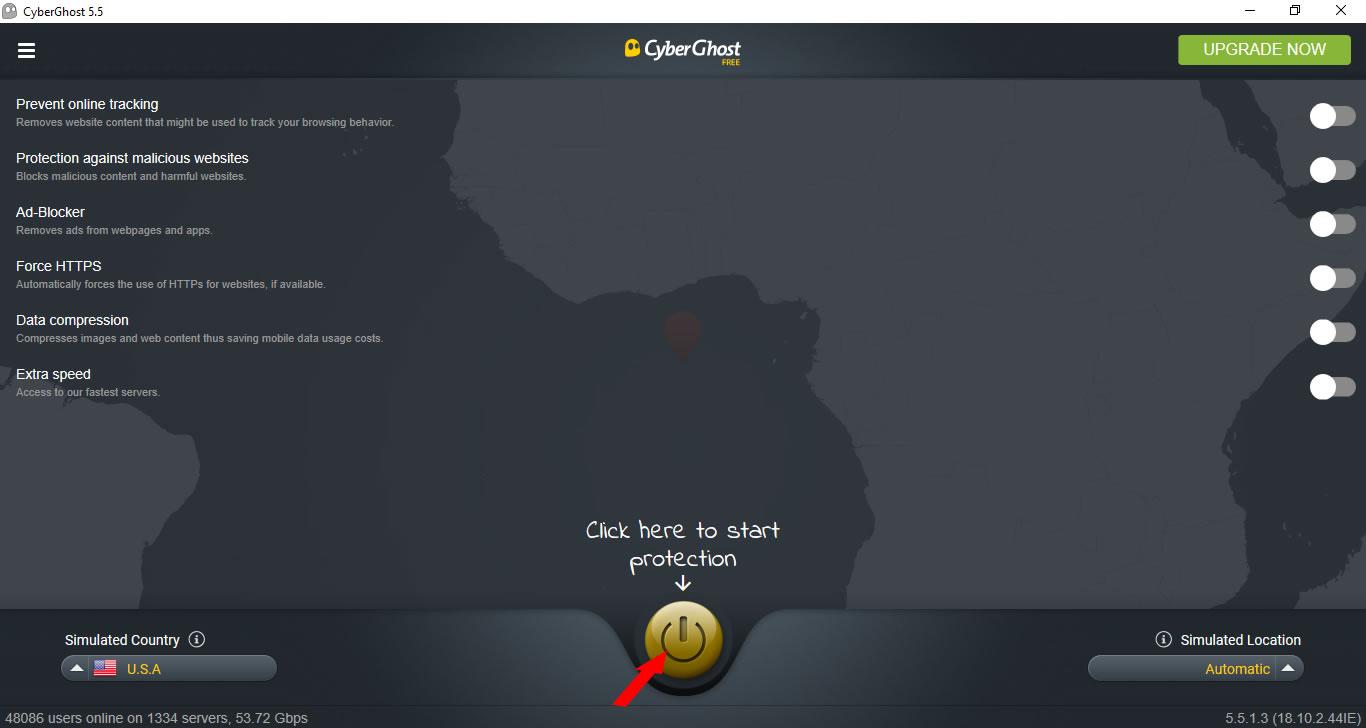
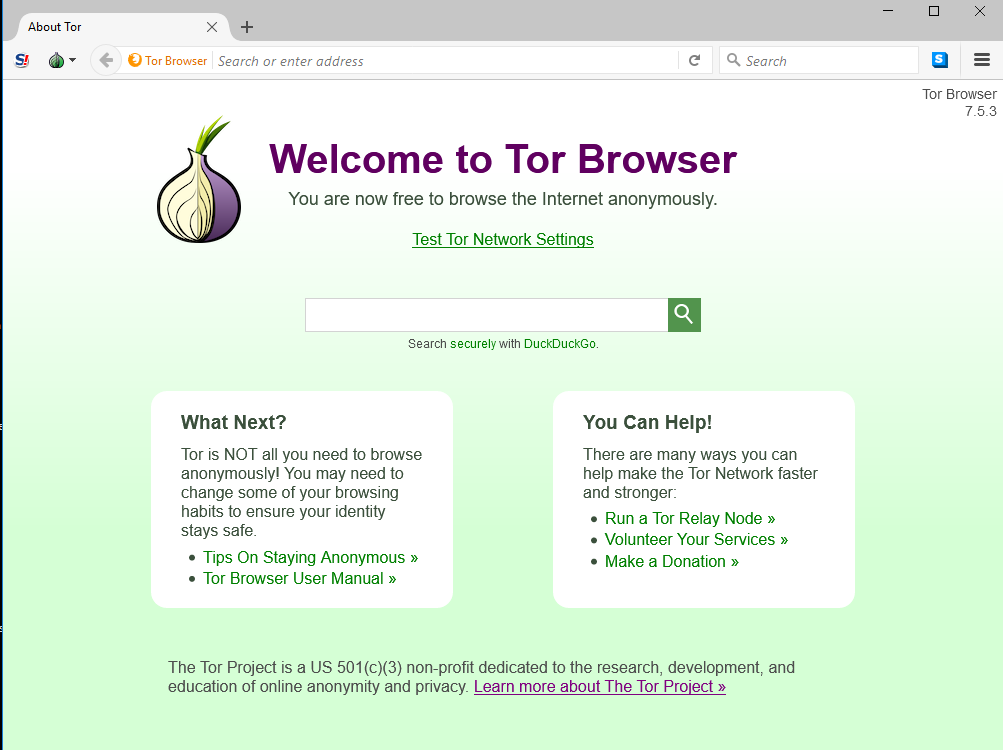
Step 2: Download and install the Tor browser bundle
Before you do though, check that your VPN is running. Also be sure to download Tor from the official Tor project website.
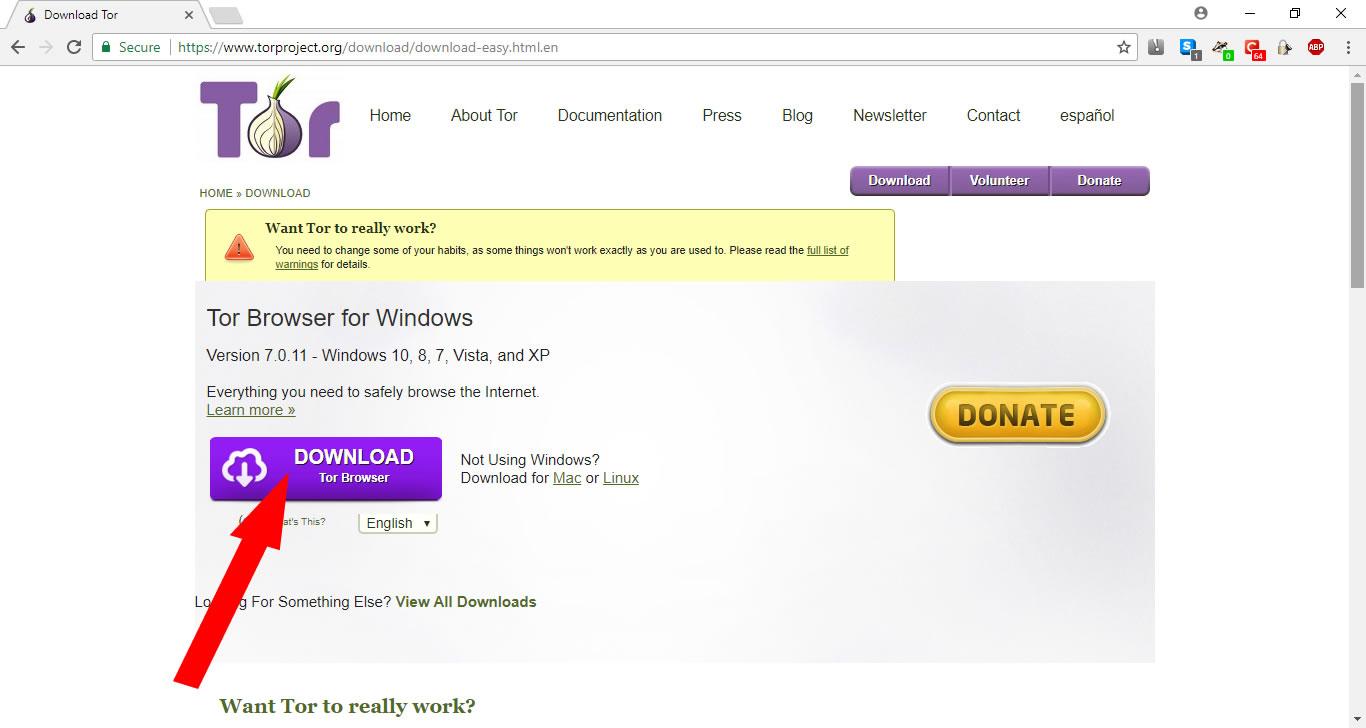
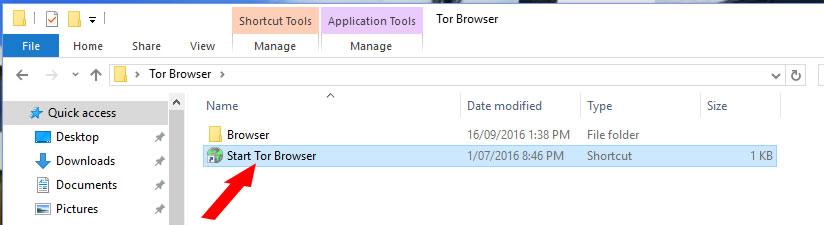
Once it’s installed, look for the Tor Browser folder and click on the “Start Tor Browser” file inside it.
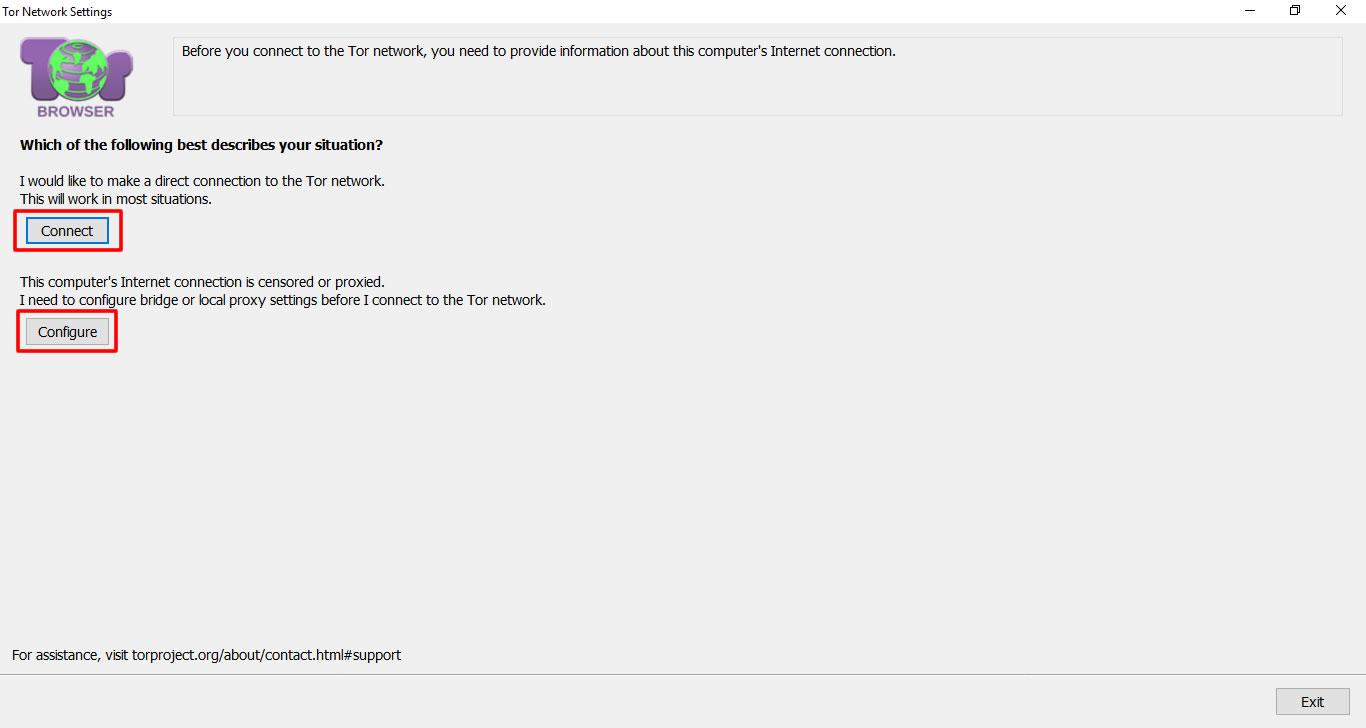
A new window will open asking you to either click on the “Connect” or “Configure” button. Click on the “Connect” option to open the browser window.
Step 3. Start browsing.onion websites
When you open Tor on your computer, you’ll automatically be directed to the search engine DuckDuckGo. While DuckDuckGo is designed to provide extra privacy and encryption while searching the web, you shouldn’t think of it as the dark web version of Google.
That’s because even in Tor, DuckDuckGo searches the clear web. That means if you do a keyword search, you’re results are going to be basically the same as what you would find on the regular internet.
Source :https://www.vpnmentor.com/blog/whats-the-dark-web-how-to-access-it-in-3-easy-steps/
Source :https://www.vpnmentor.com/blog/whats-the-dark-web-how-to-access-it-in-3-easy-steps/
Indexing methods
Indexing methods
Methods that prevent web pages from being indexed by traditional search engines may be categorized as one or more of the following:
- Contextual web: pages with content varying for different access contexts (e.g., ranges of client IP addresses or previous navigation sequence).
- Dynamic content: dynamic pages, which are returned in response to a submitted query or accessed only through a form, especially if open-domain input elements (such as text fields) are used; such fields are hard to navigate without domain knowledge.
- Limited access content: sites that limit access to their pages in a technical way (e.g., using the Robots Exclusion Standard or CAPTCHAs, or no-store directive, which prohibit search engines from browsing them and creating cached copies).
- Non-HTML/text content: textual content encoded in multimedia (image or video) files or specific file formats not handled by search engines.
- Private web: sites that require registration and login (password-protected resources).
- Scripted content: pages that are only accessible through links produced by JavaScript as well as content dynamically downloaded from Web servers via Flash or Ajax solutions.
- Software: certain content is intentionally hidden from the regular Internet, accessible only with special software, such as Tor, I2P, or other darknet software. For example, Tor allows users to access websites using the .onion server address anonymously, hiding their IP address.
- Unlinked content: pages which are not linked to by other pages, which may prevent web crawling programs from accessing the content. This content is referred to as pages without backlinks (also known as inlinks). Also, search engines do not always detect all backlinks from searched web pages.
- Web archives: Web archival services such as the Wayback Machine enable users to see archived versions of web pages across time, including websites which have become inaccessible, and are not indexed by search engines such as Google
Non-indexed content
Bergman, in a paper on the deep web published in The Journal of Electronic Publishing, mentioned that Jill Ellsworth used the term Invisible Web in 1994 to refer to websites that were not registered with any search engine. Bergman cited a January 1996 article by Frank Garcia:
Another early use of the term Invisible Web was by Bruce Mount and Matthew B. Koll of Personal Library Software, in a description of the #1 Deep Web tool found in a December 1996 press release.
The first use of the specific term deep web, now generally accepted, occurred in the aforementioned 2001 Bergman study.
Terminology
Terminology
The first conflation of the terms "deep web" with "dark web" came about in 2009 when deep web search terminology was discussed together with illegal activities taking place on the Freenet and darknet.
Since then, after their use in the media's reporting on the Silk Road, media outlets have taken to using 'deep web' synonymously with the dark web or darknet, a comparison some reject as inaccurate and consequently has become an ongoing source of confusion. Wired reporters Kim Zetter and Andy Greenberg recommend the terms be used in distinct fashions. While the deep web is a reference to any site that cannot be accessed through a traditional search engine, the dark web is a portion of the deep web that has been intentionally hidden and is inaccessible through standard browsers and methods.
Source : https://en.wikipedia.org/wiki/Deep_web
Source : https://en.wikipedia.org/wiki/Deep_web
Tuesday, 7 January 2020
Deep Web
Mike Bergman, founder of BrightPlanet who gave the term, said that searching the Internet at this time can be compared to catching fish at sea level: will get a lot of fish caught in the net, but very deep information will not be caught. Most of the information found on the Internet is buried deeply in dynamic sites, and standard web search engines cannot find it. Traditional web search engines cannot "detect" or retrieve data on the Deep Web. These pages are considered non-existent until they are created dynamically as a result of a specific search. Since 2001, the Deep Web has been declared to have a larger size than the ordinary Web.
Subscribe to:
Posts (Atom)